
在资源匮乏,搞人工智能和大数据应用没有数据,做社交应用找不到用户,开发图片应用缺少图片,的情况下,如何冷启动?
11月2日晚上8点,本文作者就爬虫话题,推出更详尽的在线直播免费公开课,欢迎各位读者扫码听课――
这可以算是最古老的一类爬虫了,第一代搜索引擎走的就是这条技术线。互联网的性决定了,所有我们能够浏览到的HTML网页的内容,都可以被爬虫抓取到。
静态网页是由简单的 HTML 文本 + JS + CSS 构成的,开发者通常最关心HTML文本,而CSS 和 JS 仍然具有很高的使用频率。通过CSS,我们可以快速定位并提取出所需要的数据,这在后续的数据清洗的时候非常有用,如果没有CSS的id 和 class,唯一可以利用的也许就只有html 的 tag 以及 正则表达式,提取数据的难度会增大很多。至于说通过JS,这是下一个故事了。
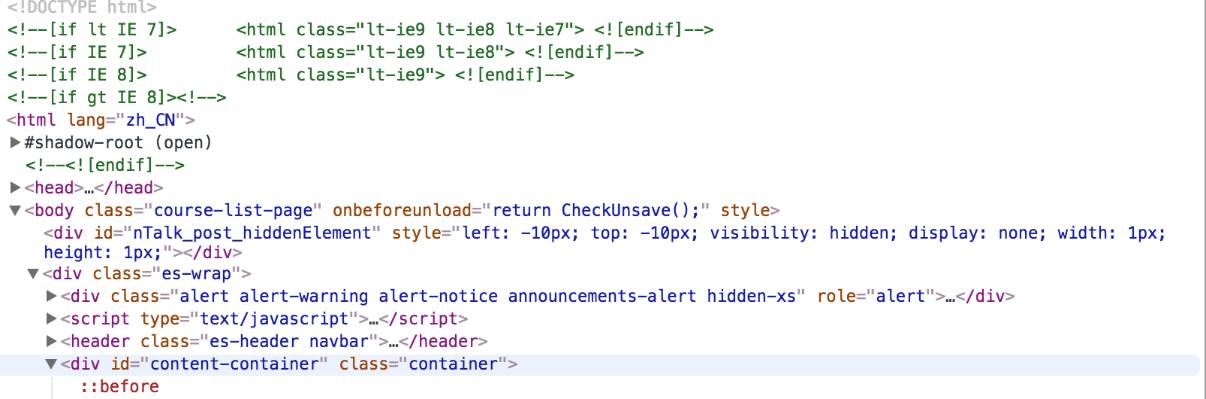
内容精彩的网页,源代码看起来通常是这个样子,而我们需要的,通常是正文部分的的核心内容,一般通过标签、CSS还有正则,就可以提取出来。实际上,我们可能会遇到各种复杂情况,有些时候我们希望以自动化的方式从中抽取内容,而不用人为地针对每个网页,使用css 等方法来抽取,在公开课里,我们会介绍如何用一些算法,自动识别正文并抽取。
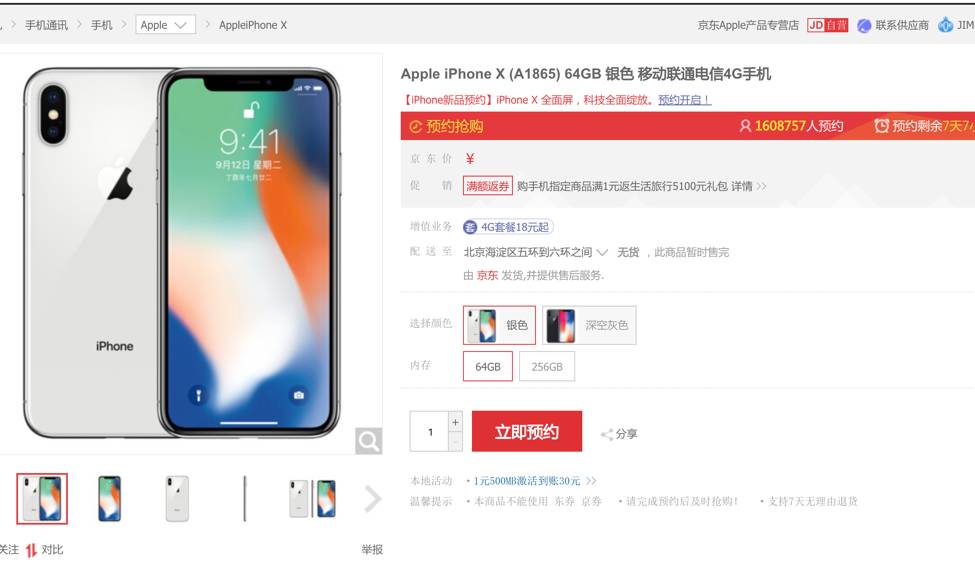
让我们一起来看这张截图,它来自京东网站的一个页面。请注意,iPhone X 的价格并没有显示出来。如果我们看到网页的源代码
会发现,在原始的 HTML 里就没有显示价格,那么价格数据在哪儿存放呢?我们需要了解的是,在动态页面中,HTML只是一个模板,而页面中的动态信息、数据,都是由程序异步的方式填上去的,这个程序就是java。
对于这样的情况,我们直接抓取 HTML 是没有用的,价格信息并不包含在 HTML 里,所以我们需要使用一些别的技术来获取到价格数据,这里先卖个关子。
11月2日晚上8点,本文作者就爬虫话题,推出更详尽的在线直播免费公开课,欢迎各位读者扫码听课――
在移动互联网时代,HTML 网页所提供的内容已经极大减少了,现在几乎没有哪个主流的应用不支持移动端,倒是有很多应用只有移动端而没有网站,因此当我们需要获取此类应用的数据时,传统的HTML爬虫就不管用了。
说到微信号,我们必须了解的是:移动APP大致可分为两大类应用:H5 应用及原生APP,这两者有什么区别呢?H5的应用本质上是在本地用H5页面进行呈现,也就是说,我们所看到的应用页面本质上是一个网页,比如微信号就是这样的,我们所看到的每一篇号文章其实就是一个网页,APP 使用内嵌的 WebView 来加载和渲染 HTML 网页,这其实跟浏览器的功能完全一样;另一类就是原生APP了,比如微博的瀑布流,这里用的是native 控件来展示。使用native 控件时,布局都是在程序里预设好的。

的截图来自QQ音乐,我们看到的所有蓝色部分都是动态数据,包括中间的音乐专辑封面。这些数据可以是本地的,也可以来自网络请求,如果从网络请求,通常是 HTTP 协议,我们通过抓包工具可以拿到这些数据。
在native app 里,经常也会使用 H5 来渲染,但这跟微信号是有区别的。我们知道,HTML相对于普通APP有一个很大的优势,就是复杂元素的布局上,我们可以基于HTML的规则,让浏览器(WebView)动态给元素布局,而在原生APP中,没一个元素的摆放,需要程序去设定。所以,对于图文混合的文章来说,使用原生APP 动态解析、布局非常困难,这时交给HTML 网页就简单了。例如这篇网易新闻的文章,有标题、图片、文字,每一篇文章的标题文字排版都不同,通过 HTML 技术,简单地使用下面的形式就可以解决,但使用native的方会复杂很多。
这里是一个模板,从原始的 widget 变成了HTML,其中数据部分是单独通过接口获取的,这与微信号那一类完全获取整个HTML 仍然有本质的区别,简单说,就是如果抓包的话,我们会看到的微信号的数据是网站的HTML 网页,而在网易新闻客户端,通常会看到一个 JSON 格式的响应。
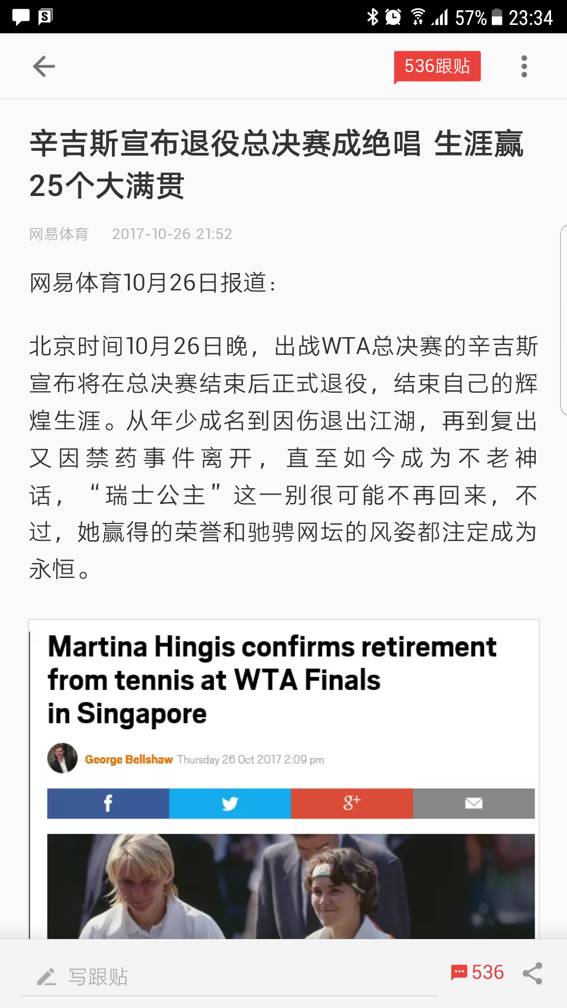
为什么会有这样的区别呢?因为微信号是每个号平台自己定义的,而网易新闻的文章格式是固定的,所以HTML可以把模板和内容拆开,把模板存储在应用里,而内容则从网络获取,从而大大节省每次网络请求的开销。
APP 里的内容抓取,无论是从内嵌HTML还是纯粹的数据接口,都会比较困难。除了要学会抓包、反编译,通常还要能看懂二进制或者混淆过的Java代码,能从一些蛛丝马迹去寻找我们需要的关键数据。这是为什么呢?因为HTML的解析工作是在浏览器上,浏览器是所有网站共享的,大家必须遵从HTTP 协议以及HTML 的规范,因为这是标准的,也就是的,所以各个网站能自定义的东西不多;而APP就不一样了,数据如何传输,如何加密,格式怎么定,都是我自己说了算,不需要也根本就不想让别人能看懂。
除了微信号,我还会介绍如何从淘宝、京东、微博这些网站抓取数据,每个网站都有自己的特点,我们应使用不同的方法,例如,针对淘宝和京东,我们可采用动态网页的方式进行抓取;而对于微博,我们则直接分析它的网络请求,找出微博的数据接口,直接通过接口来获取,这个效率比起一般的网络请求 + 解析要快得多。

最后是一个大家特别关心的问题,就是如何应对反爬虫。在这个领域,我们也拥有丰富的经验,包括Google、微信号、马蜂窝这些做了非常严格的反爬虫措施的网站,我们也仍然可以做到每天10万量级的抓取速度,具体会在公开课介绍给大家。
既然是分布式爬虫,说明我们整套系统是基于分布式的。分布式有非常多的好处,其中一方面就是在应对网站的反爬上,除此之外,分布式系统还具有一些非常明显的优势:
借着分布式系统,我们也会介绍 IAAS +PAAS 这样的技术,在实际使用中,IAAS 这样的虚拟化技术,对于分布式爬虫系统的管理和非常重要。
最后,我们会介绍爬虫的延展应用,比如文本抽取、分类、搜索等。数据的抓取和清洗以及两个重要的文本应用:分类与检索,这是几乎任何一套包含爬虫的数据系统里不可缺少的。
11月2日晚上8点,本文作者就爬虫话题,推出更详尽的在线直播免费公开课,欢迎各位读者扫码听课――返回搜狐,查看更多
推荐:


网友评论 ()条 查看