
有一篇有关爬取P2P网站上散标投资数据和借贷人的信息数据的博文,整合前人资料(),说一下爬取中遇到的问题:
后在上图中左侧点击到第2个页面,右侧那一栏会弹出3个事件(对其中Method为GET的那一个事件进行分析)

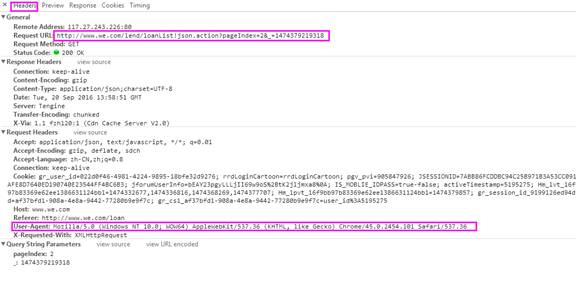
仔细观察Request URL:,你会发现数据是Json格式,查看下一页,发现也是如此,不同页面的数据格式是相同的。对此,我们的抓取思就是:获取网页源代码,从源代码中提取数据。
数据来自于类似这样的地址:删除&_=11后的链接依然有效,打开链接发现是json格式的数据,而且数据就是当前页面的数据。至此,我们就找到了真正的数据来源。
(页面总共51个,可自己写个循环语句,但循环过程中可能出错,我自己就是一个个页面爬取的,然后再把51个页面的数据loan整合)
总的来说,第一步为得是给第二步做铺垫,因为第二步需要用到第一步中loans.csv中的loanId,可自行将其单独整理为一个csv文档。
推荐:


网友评论 ()条 查看